Independent AI research lab · Filip & Dr. Juraj KoščákExact-or-abstain systems · measured on real hardware
Intelligence that proves,
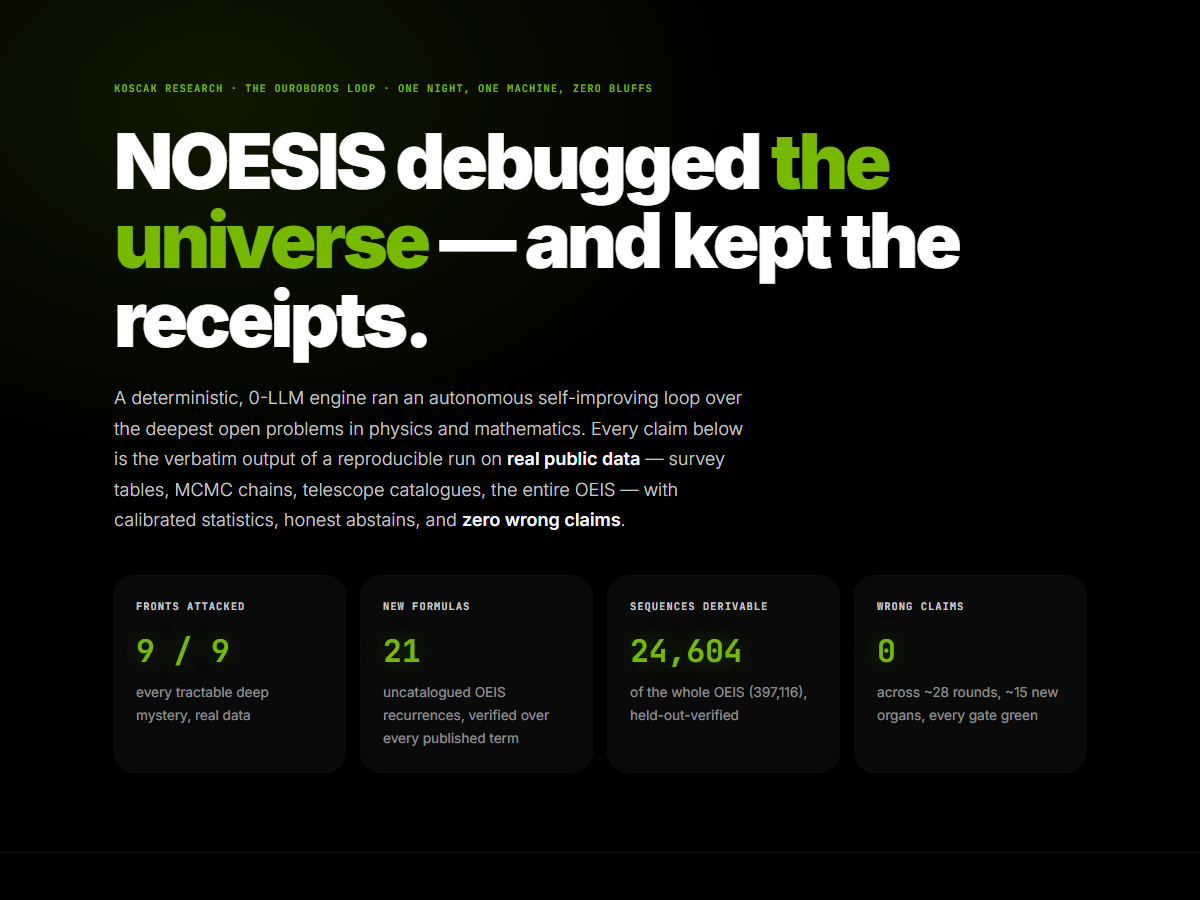
instead of guessing.Exact, or it abstains.
We are Filip and Juraj Koščák, nephew and uncle, a builder and a scientist. We started this lab because we were tired of AI that sounds certain and is quietly wrong. Everything we make follows one rule: measure it, or don't claim it.A two-person lab across ML engineering and stochastic-learning research. Every system ships under one constraint: verified against held-out reality, or it abstains. No cherry-picking, no confident bluffing.
One standard across every program · proof, not promisesHeld-out verification · exact-or-abstain · reproducible logs